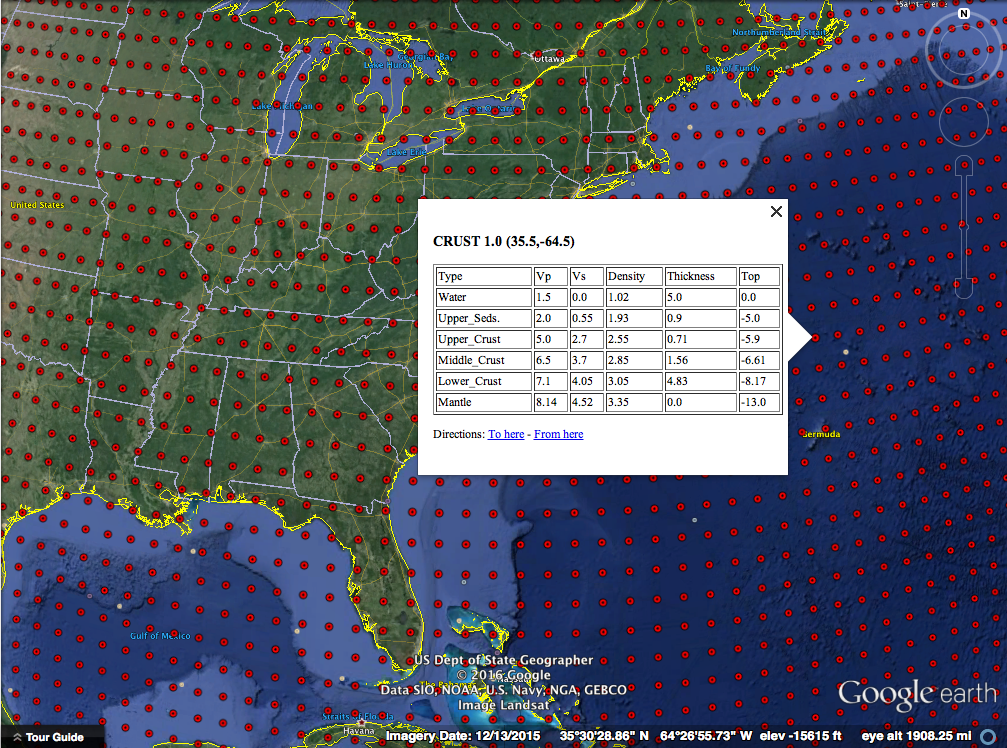
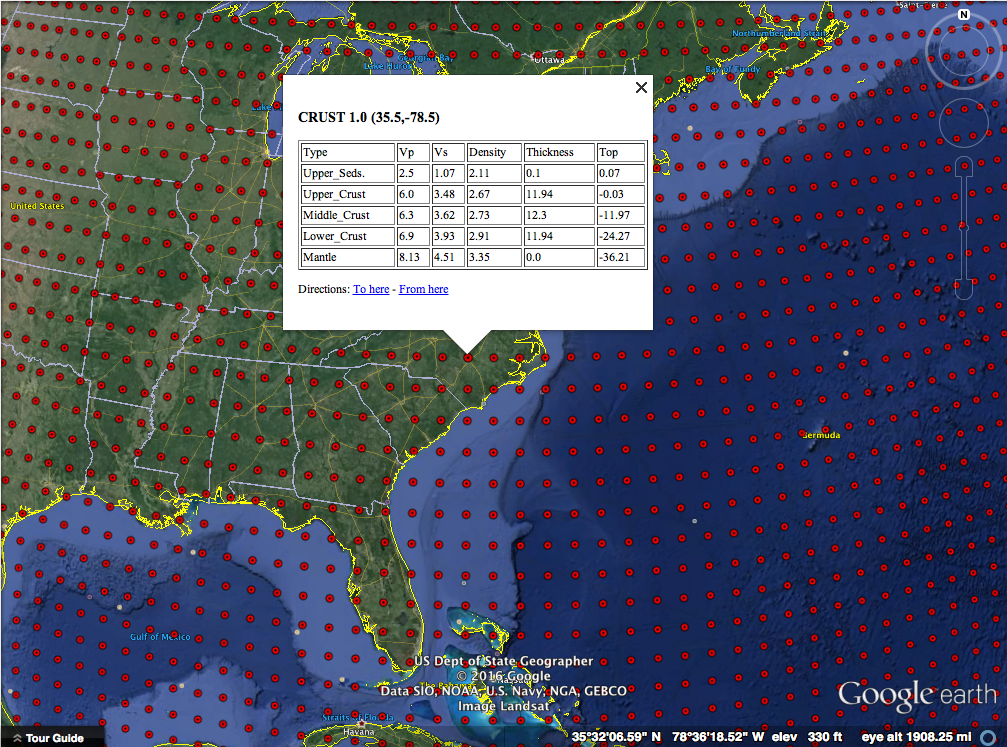
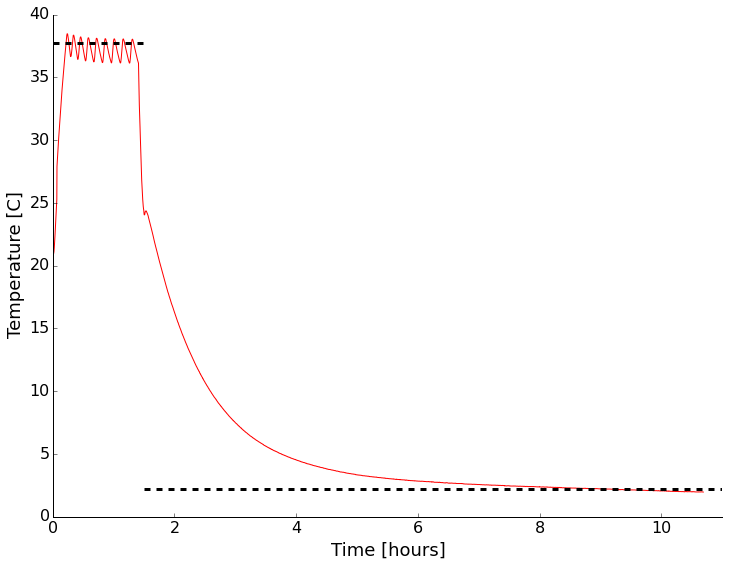
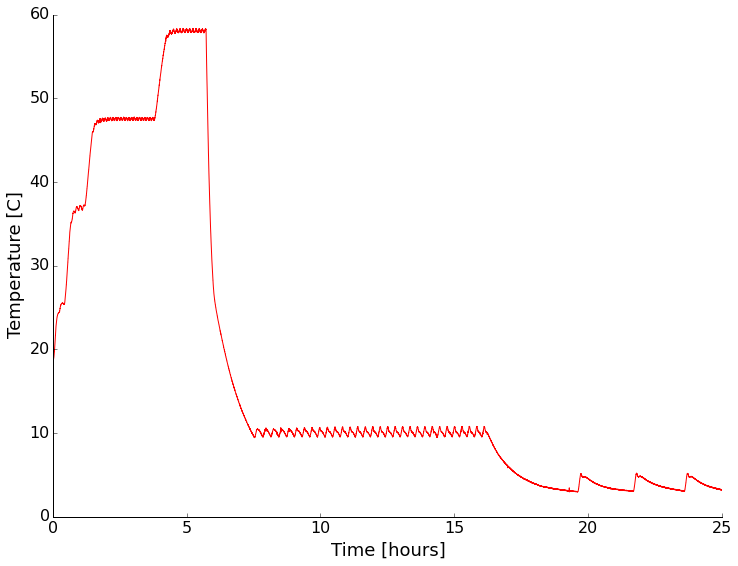
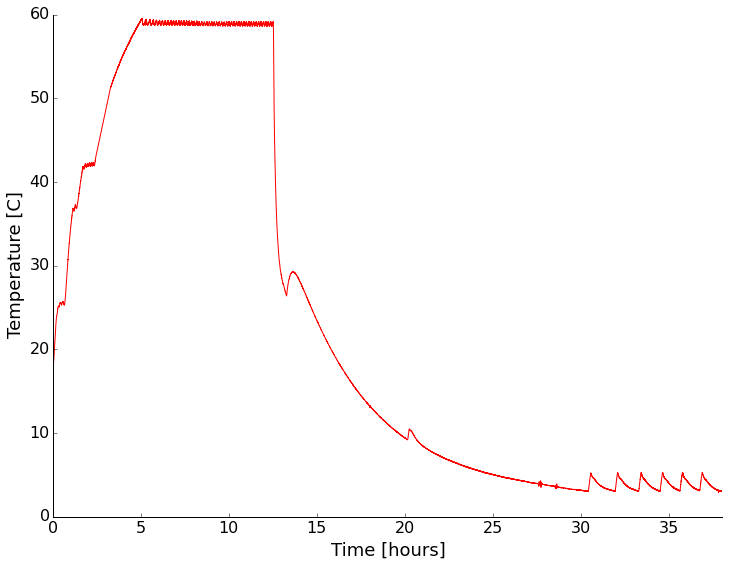
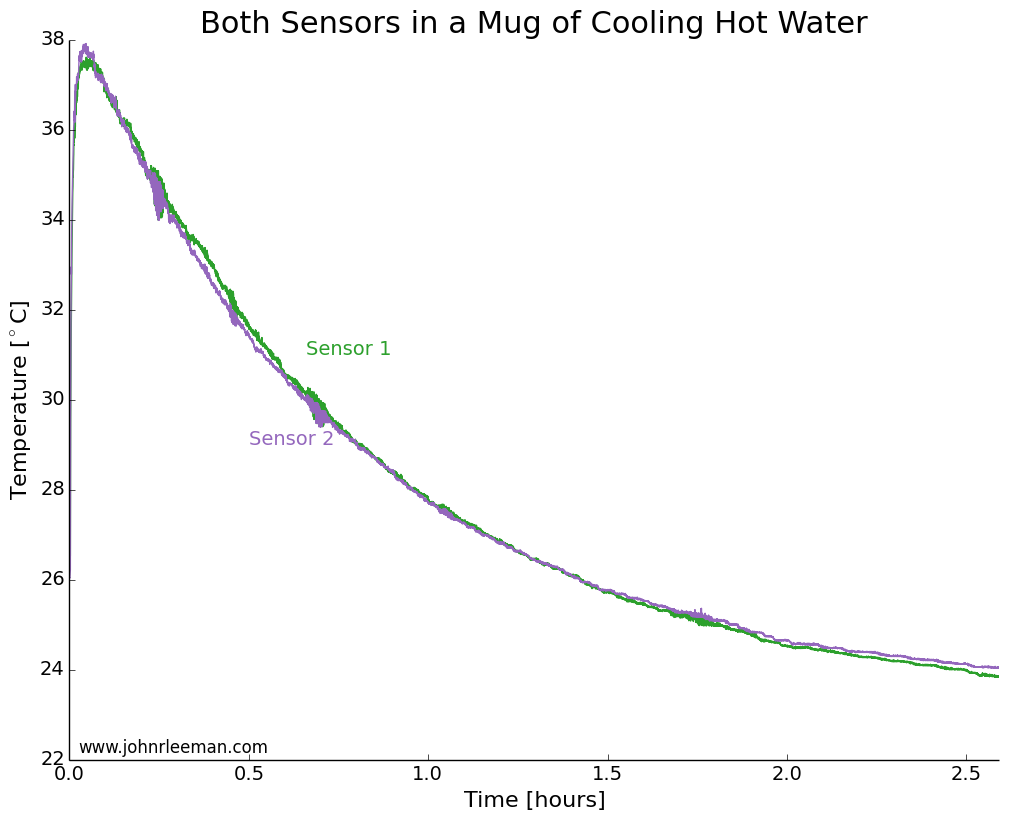
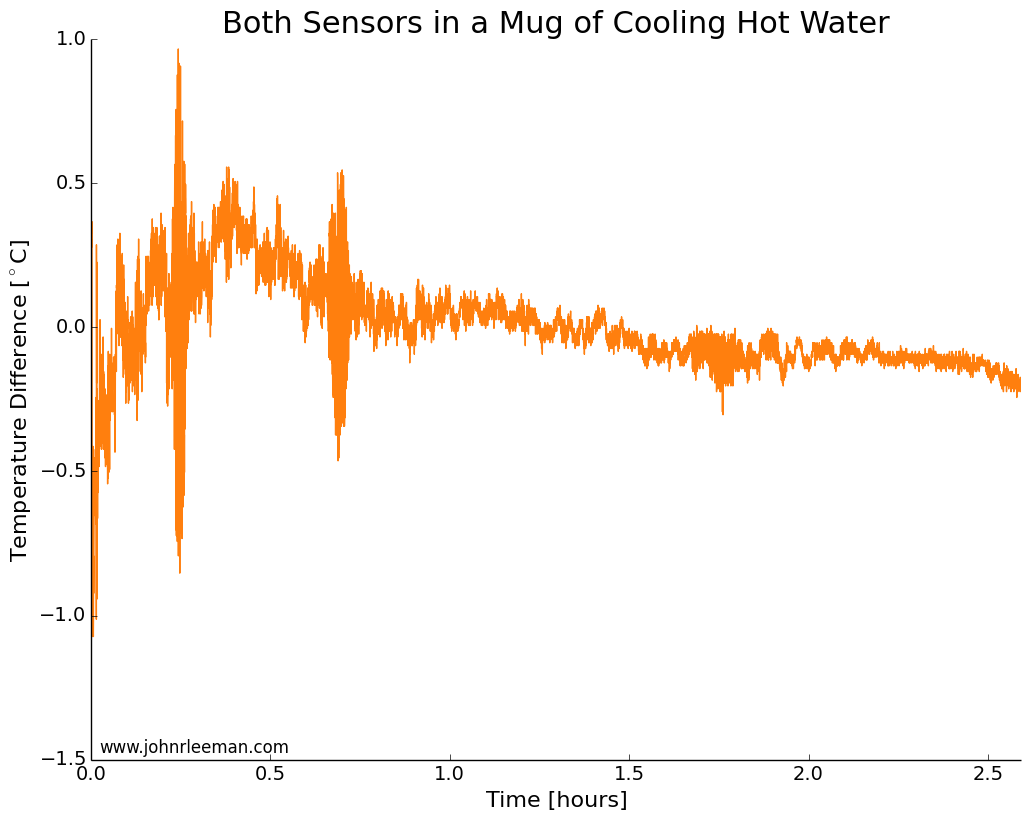
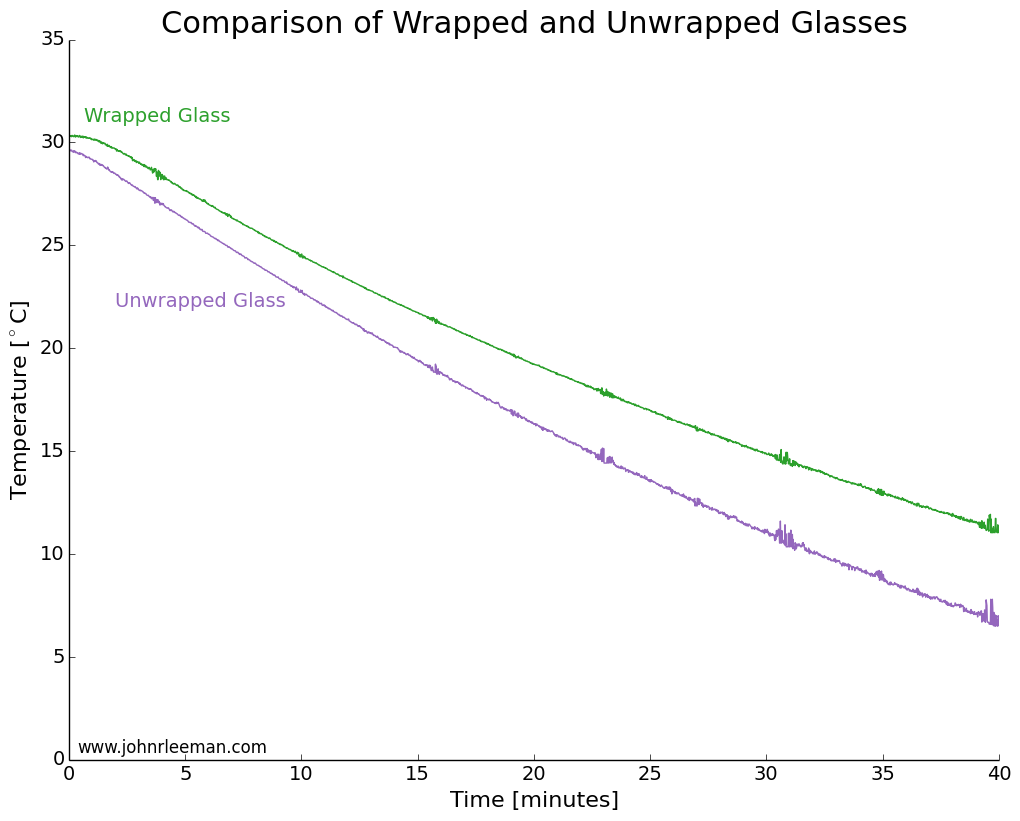
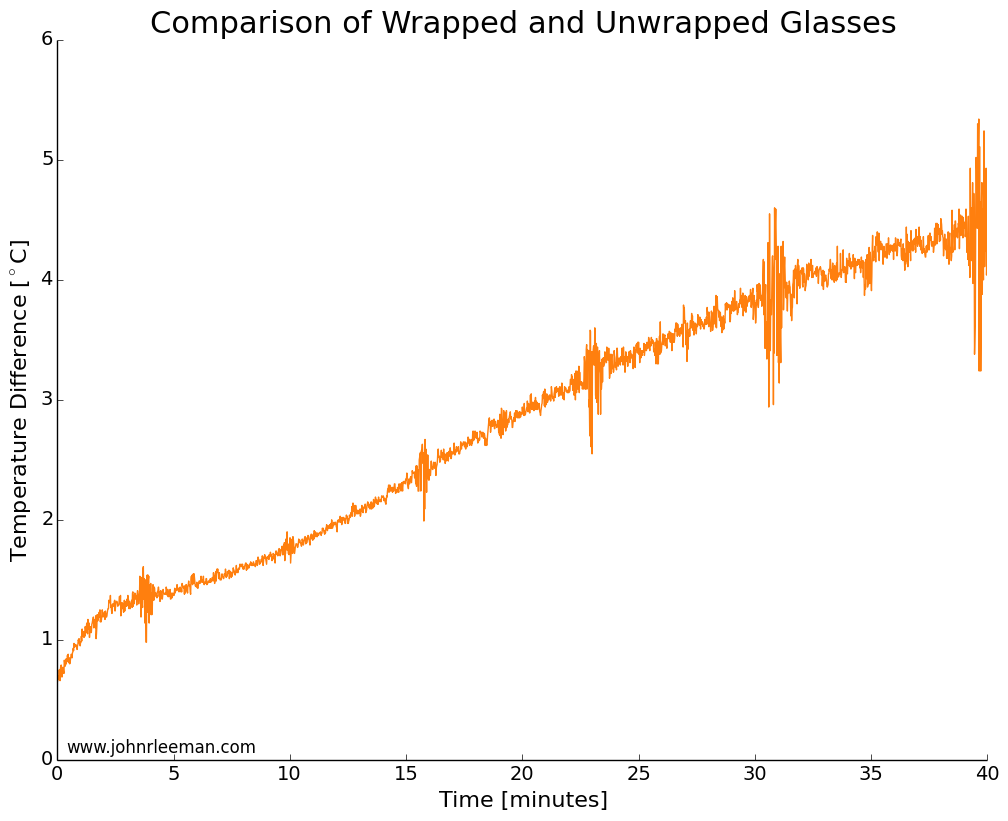
For the second installment in our summer open science series, I’d like to talk about open data. This could very well be one of the more debated topics; I certainly know it always gets my colleagues opinions exposed very quickly in one direction or the other. I’d like to think about why we would do this, methods and challenges of open data, and close with my personal viewpoint on the topic.
What is Open Data?
Open data simply means putting data that supports your scientific arguments in a publicly available location for anyone to download, replicate your analysis, or try new kinds of analysis. This is now easier than ever for us to do with a vast array of services that offer hosting of data, code, etc. The fact that every researcher will likely have a fast internet connection makes most arguments about file size invalid, with the exception of very large (100’s of gigabytes) files. The quote below is a good starting place for our discussion:
Numerous scientists have pointed out the irony that right at the historical moment when we have the technologies to permit worldwide availability and distributed process of scientific data, broadening collaboration and accelerating the pace and depth of discovery…..we are busy locking up that data and preventing the use of correspondingly advanced technologies on knowledge.
- John Wilbanks, VP Science, Creative Commons
Why/Why-Not Open Data?
When I say that I put my data “out-there” for mass consumption, I often get strange looks from others in the field. Sometimes it is due to not being familiar with the concept, but other times it comes with the line “are you crazy?” Let’s take a look at why and why-not to set data free.
First, let’s state the facts about why open data is good. I don’t think there is much argument on these points, then we’ll go on to address more two-sided facets of the idea. It is clear that open data has the potential to increase the friendliness of a group of knowledge workers and the ability to increase our collaboration potential. Sharing our data enables us to pull from data that has been collected by others, and gain new insights from other’s analysis and comments on our data. This can reduce the reproduction of work and hopefully increase the numbers of checks done on a particular analysis. It also gives our supporters (tax payers for most of us) the best “bang for their buck.” The more places that the same data is used, the cost per bit of knowledge extracted from it is reduced. Finally, open data prevents researchers from taking their body of knowledge “to the grave” either literally or metaphorically. Too often a grad student leaves a lab group to go on in their career and all of their data, notes, results, etc that are not published go with them. Later students have to reproduce some of the work for comparison using scant clues in papers, or email the original student and ask for the data. After some rummaging, they are likely emailed a few scattered, poorly formatted spreadsheets with some random sampling of the data that is worse than no data at all. Open data means that quality data is posted and available for anyone, including future students and future versions of yourself!
Like every coin, there is another side to open data. This side is full of “challenges.” Some of these challenges even pass the polite term and are really just full-blown problems. The biggest criticism is wondering why someone would make the data that they worked very hard to collect out in the open, for free, to be utilized by anyone and for any purpose. Maybe you plan on mining the data more yourself and are afraid that someone else will do that first. Maybe the data is very costly to collect and there is great competition to have the “best set” of data. Whatever the motivation, this complaint is not going to go away. Generally my reply to these criticisms goes along the lines of data citation. Data is becoming a commodity in any field (marketing, biology, music, geology, etc). The best way to be sure that your data is properly obtained is to make it open with citation. This means that people will use your data, because they can find it, but provide proper credit. There are a number of ways to get your data assigned a digital object identifier (DOI), including services like datacite. If anything, this protects the data collector by providing a time-stamp of doing data collection of phenomena X at a certain time with a time-stamped data entry. I’m also very hopeful that future tenure committees will begin to recognize data as a useful output, not just papers. I’ve seen too many papers that were published as a “data dump.” I believe that we are technologically past that now, if we can get past "publish or perish," we can stop these publications and just let the data speak for itself.
Another common statement is “my data is too complicated/specialized to be used by anyone else, and I don’t want it getting mis-used.” I understand the sentiment behind this statement, but often hear it as “I don’t want to dedicate time to cleaning up my data, I’ll never look at it after I publish this paper anyway.” Taking the time to clean up data for it to be made publicly available is when you have a second chance to find problems, make notes about procedures and observations, and make it clear exactly what happened during your experiment (physical or computational). I cannot even count the number of times I’ve looked back at old data and found notes to myself in the comments that helped guide me through re-analysis. These notes saved hours of time and possibly a few mistakes along the way.
Data Licensing
Like everything from software to intellectual property, open-data requires a license to work. No license on data is almost worse that no data at all because the hands of whoever finds it are legally bound to do nothing with it. There is even a PLOS article about licensing scientific software that is a good read and largely applies to data.
What data licensing options are available to you are largely a function of the country you work in and you should talk with your funding agency. The country or funding agency may limit the options you have. For example, any US publicly funded research must be available after a presidential mandate that data be open where possible “as a public good to advance government efficiency, improve accountability, and fuel private sector innovation, scientific discovery, and economic growth.” You can read all about it in the White House U.S. Open Data Action Plan. So, depending on your funding source you may be violating policy by hoarding your data.
There is one exception to this: Some data are export controlled, meaning that the government restricts what can be put out in the open for national security purposes. Generally this pertains to projects that have applications in areas such as nuclear weapons, missile guidance, sonar, and other defense department topics. Even in these cases, it is often that certain parts of the data may still be released (and should be), but it is possible that some bits of data or code may be confidential. Releasing these is a good way to end up in trouble with your government, so be sure to check. This generally applies to nuclear and mechanical engineering projects and some astrophysical projects.
File Formats
A large challenge to open data is the file formats we use to store our data. Often times the scientist will use an instrument to collect their data that stores information in a manufacturer specific, proprietary format. It is analyzed with proprietary software and a screen-shot of the results included in the publication. Posting that raw data from the instrument does no good since others must have the licensed and closed-source software to even open it. In many cases, the users pay many thousands of dollars a year for a software “seat” that allows them to use the software. If they stop paying, the software stops working… they never really own it. This is a technique that the instrument companies use to ensure continued revenue. I understand the strategy from a business perspective and understand that development is expensive, but this is the wrong business model for a research company. Especially considering that the software is generally difficult to use and poorly written.
Why do we still deal in proprietary formats? Often it is because that is what the software we use has, as mentioned above. Other times it is because legacy formats die hard. Research groups that have a large base of data in an outdated format are hesitant to update the format because it involves a lot of data maintenance. That kind of work is slow, boring, and unfunded. It’s no wonder nobody wants to do it! This is partially the fault of the funding structure, and unmaintained data is useless data and does not fulfill the “open” idea. I’m not sure what the best way to change this idea in the community is, but it must change. Recent competitions to “rescue” data from older publications are a promising start. Another, darker, reason is that some researches want to make their data obscure. Sure, it is posted online, so they claim it is “open”, but the format is poorly explained or there is no meta-data. This is a rare case, but in competitive fields can be found. This is data hoarding in the ugliest form under the guise of being open.
There are several open formats that are available for almost any kind of data including plain text, markdown, netCDF, HDF5, and TDMS. I was at a meeting a few years ago where someone argued that all data should be archived as Excel files because “you’ll always be able to open those.” My jaw dropped. Excel is a closed, XML based, format that you must have a closed-source program to open. Yes, Open Office can open those files, but compatibility can be sketchy. Stick to a format that can handle large files (unlike Excel), supports complex multi-dimensional data (unlike Excel), and has many tools in many languages to read/write it (unlike Excel).
The final format/data maintenance task is a physical format concern. Storage media changes with time. We have transitioned from tapes, floppy disks, CDs, and ZIP disks to solid state storage and large external hard-drives. I’m sure some folks have their data on large floppy disks, but haven’t had a computer to read them in years. That data is lost as well. Keeping formats updated is another thankless and unfunded task. Even modern hard-drives must be backed up and replaced after a finite shelf life to ensure data continuity. Until the funding agencies realize this, the best we can do is write in a small budget line-item to update our storage and maintain a safe and useful archive of our data.
Meta-Data
The last item I want to talk about in this already long article is meta-data. Meta-data, as the name implies, are data about the data. Without the meta-data, most data are useless. Data must be accompanied by the experimental description, relevant parameters (who, when, where, why, how, etc), and information about what each data item means. Often this data lives in the pages of the laboratory notebooks of experimenters or on scraps of paper or whiteboards for modelers. Scanners with optical character recognition (OCR) can help solve that problem in many cases.
The other problems with meta-data are human problems. We think we’ll remember something, or we don’t have time to collect it. Anytime that I’ve thought I didn’t have time to write good notes, I payed by spending much more time after the fact figuring out what happened. Collecting meta-data is something we can’t ever do enough of and need to train ourselves to do. Again, it is a thankless and unfunded job… but just do it. I’ve even just turned on a video or audio recorder before and dictated what I’m doing. If you are running a complex analysis procedure, flip on a screen capture program and make a video of doing it to explain it to your future self and anyone else who is interested.
Meta-data is also a tricky beast because we never know what to record. Generally, record everything you think is relevant, then record everything else. In rock mechanics we generally record stress conditions, but never think to write down things like temperature and humidity in the lab. Well, we never think to until someone proves that humidity makes a difference in the results. Now all of our old data could be mined to verify/refute that hypothesis, except we don’t have the meta-data of humidity. While recording everything is impossible, it is wise to record everything that you can within a reasonable budget and time commitment. Consistency is key. Recording all of the parameters every time is necessary to be useful!
Final Thoughts
Whew! That is a lot of content. I think each item has a lot unsaid still, but this is where my thinking currently sits on the topic. I think my view is rather clear, but I want to know how we can make it better. How can we share in fair and useful ways? Everyone is imperfect at this, but that shouldn’t stop us from striving for the best results we can achieve! Next time we’ll briefly mention an unplanned segment on open-notebooks, then get on to open-source software. Until then, keep collecting, documenting, and sharing. Please comment with your thoughts/opinions!
 Folks that follow my various projects have probably noticed that I've recently formed an instrumentation and consulting company. I've had great fun doing several jobs for folks ranging from CAD design of brackets to writing numerical models for projects to designing custom measurement solutions. I've also been very busy designing some exciting new hardware that I hope will be available soon. In this post I wanted to share a time saving trick I used in KiCad while designing my printed circuit boards for one of these projects.
Folks that follow my various projects have probably noticed that I've recently formed an instrumentation and consulting company. I've had great fun doing several jobs for folks ranging from CAD design of brackets to writing numerical models for projects to designing custom measurement solutions. I've also been very busy designing some exciting new hardware that I hope will be available soon. In this post I wanted to share a time saving trick I used in KiCad while designing my printed circuit boards for one of these projects.